FPGAs are widely used in the Test and Measurement (T&M) industry for their capabilities in high-speed signal processing, high precision data processing, and general design flexibility. As market demand for faster and more precise instrumentation increases, T&M FPGA designs also become more complex and more challenging in terms of timing closure – directly impacting Time-to-Market.
This article discusses how a new design optimization approach known as the InTime Timing Closure Methodology was recently used to increase the FMax, as well as to optimize and close timing for five large, routing-congested T&M designs within a week. Based on machine learning, this new approach is baked into the InTime design optimization software tool.
Design Background
Device: Xilinx Virtex Ultrascale xcvu190
Although FPGA resource utilization was relatively low, numerous SLR crossings and high routing congestion make it difficult to reduce the number of failing paths in these designs. The estimated routing congestion for one of the T&M designs:
INFO: [Route 35-449] Initial Estimated Congestion ________________________________________________________________________ | | Global Congestion | Long Congestion | Short Congestion | | |___________________|___________________|___________________| | Direction | Size | % Tiles | Size | % Tiles | Size | % Tiles | |___________|________|__________|________|__________|________|__________| | NORTH| 64x64| 3.53| 32x32| 6.04| 64x64| 6.29| |___________|________|__________|________|__________|________|__________| | SOUTH| 64x64| 6.64| 64x64| 8.08| 64x64| 8.43| |___________|________|__________|________|__________|________|__________| | EAST| 32x32| 2.41| 16x16| 1.85| 32x32| 6.72| |___________|________|__________|________|__________|________|__________| | WEST| 64x64| 4.26| 32x32| 2.92| 128x128| 14.73| |___________|________|__________|________|__________|________|__________|
Before & After InTime Optimization
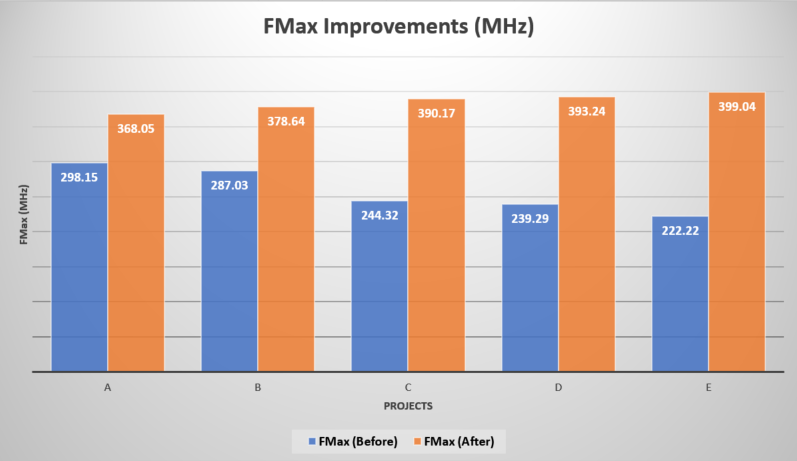
Here are the FMax Improvements. You can see that there are between 23% to 79.7% improvements in FMax using this method.
| Project Name | WNS (Before) | WNS (After) | TNS (Before) | TNS (After) | WNS Improvements | TNS Improvements |
FMax (Before) | FMax (After) |
| A | -0.854 | -0.217 | -16961.285 | -582.23 | 74.59% | 96.57% | 298.15 | 368.05 |
| B | -0.984 | -0.141 | -9496.21 | -127.48 | 85.67% | 98.66% | 287.03 | 378.64 |
| C | -1.593 | -0.063 | -1972.426 | -6.406 | 96.05% | 99.68% | 244.32 | 390.17 |
| D | -1.679 | -0.043 | -21123.871 | -0.137 | 97.44% | 100.00% | 239.29 | 393.24 |
| E | -2.0 | -0.006 | -72974.359 | -0.006 | 99.70% | 100.00% | 222.22 | 399.04 |
* Rounded up to 3 decimal places
Massive Productivity Gain – Results in 6 days
Although not all designs closed timing, this approach can significantly increase the FMax and improve the timing results in an automated fashion. The builds were accelerated through cloud computing (AWS) and the entire optimization process was driven by the InTime software. All five designs were optimized at the same time in only six days. Compared to solely focusing on iterative improvements, this represents a massive productivity gain for the entire organization.
- Actual Wait Time: 1.32 to 6.24 days
- Average Cloud Hours / Project: 957 hours
- Server Type: 4 CPU, 31 Gb RAM
How to optimize routing-congested designs – InTime Timing Closure Methodology
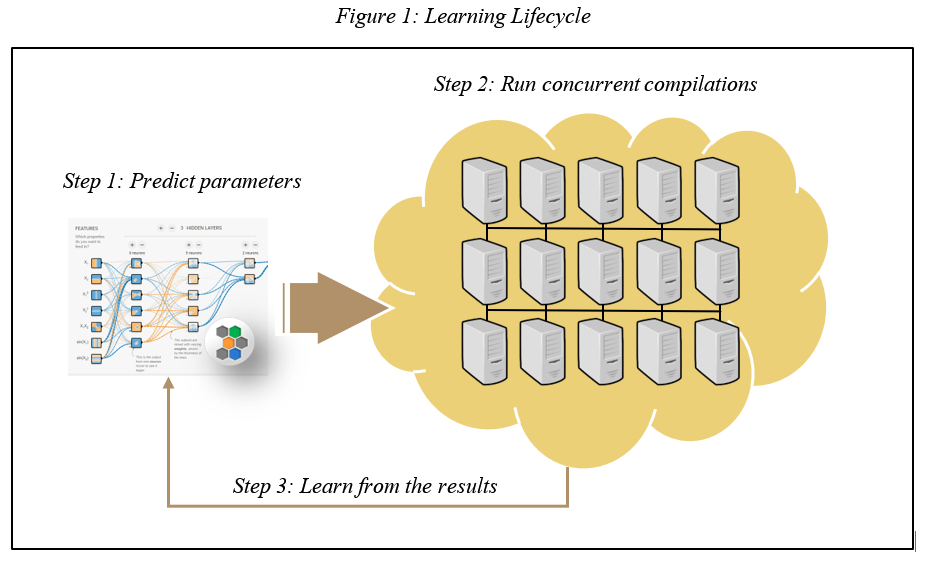
Under the InTime Timing Closure Methodology, the build process is no longer a one-designer-to-one-machine operation. Instead, it is a systematic series of calculated steps done by one or many designers on multiple build machines. From the resulting analysis, InTime deduces and recommends sets of good build parameters aimed at improving design performance.
Explore Build Parameters
Routing congestion was a significant bottleneck for the five projects mentioned above. With this in mind, one approach was to explore relevant synthesis build parameters on all the designs. As this is a machine learning-driven software, multiple builds were necessary to generate data points for analysis. InTime is able to leverage on the compute resources in the cloud, running up to 200 servers concurrently for 12 hours, massively accelerating turnaround and time to results.
Note: In Vivado, there are more than 30 build parameters, making up more than 1 billion different combinations. A classic brute-force approach will not work and will be terribly inefficient. At the other end of the spectrum, using a traditional iterative “change RTL, Build again and Repeat” is too time-consuming.
Fortunately, cloud computing has commoditized compute power into CPU-hours, and through InTime’s disciplined process and methodology, InTime is able to converge onto good results efficiently. It takes between 26 to 414 builds to achieve the results shown above. Comparing with more than 1 billion combinations, this is a tiny number. This is possible as InTime runs with a trained database that accumulates all the previous analysis from a diverse pool of designs.
Optimize Placement
Another key to optimizing a routing-congested design is to ensure good design placement. InTime has a “Placement Exploration” strategy akin to the old “Cost Tables” for ISE or Seed Sweep approach. This strategy is extremely effective for designs with negative slacks in the hundreds of picoseconds. It does not affect functionality and is safe and easy to use for timing closure.
Will this work for your design? Minimizing Risk and Increasing Chances of Meeting Timing
If you are uncertain about whether this approach will work for your design, you are more than welcome to take a free evaluation of InTime.
Please refer to the methodology guide section on results convergence. There are specific guidelines to check the likelihood of meeting timing for any design in general. Additionally, other tips such as how to reduce turnaround time for your builds may be helpful.
The other alternative is to consider InTime Service. InTime Service is a completely risk-free approach where Plunify helps you to ascertain if the design can be optimized to your requirements.
For more information about InTime, please subscribe to our blog at https://blog.plunify.com or contact us at tellus@plunify.com. A copy of the methodology guide can be downloaded here.